It took couple of week for me to get started Adobe CQ5 and Hybris together on my local desktop since Adobe Wiki is very useful but i think has not been updated for some time. Hybris is eCommerce platform now by SAP and to get the license is not easy either you have to be customer or partner. Thanks to Adobe they have created OSGI Package of Hybris server and shared in package share and also Geomtrixx outdoor eCommerce related product content.
Day wiki http://dev.day.com/docs/en/cq/current/ecommerce/eCommerce-hybris.html is usefull but need to be updated with new information.
This is really cool if you want to start up AEM eCommerce Integration framework.
https://seminars.adobeconnect.com/_a227210/p85ixyvw3zp/?launcher=false&fcsContent=true&pbMode=normal
Brief synopsis to get started.
If you have CQ5 running instance i.e 5.6.1, please create a Adobe CQ share package credentials and login into that and download Hybris 500 MB+ package that has inbuilt Hybris server and also hybris content that has hybris importer and certain content.
Install both packages in your local package manager and can access hybris console on this http://localhost:9001/hmc/hybris.and your CQ on 4502.
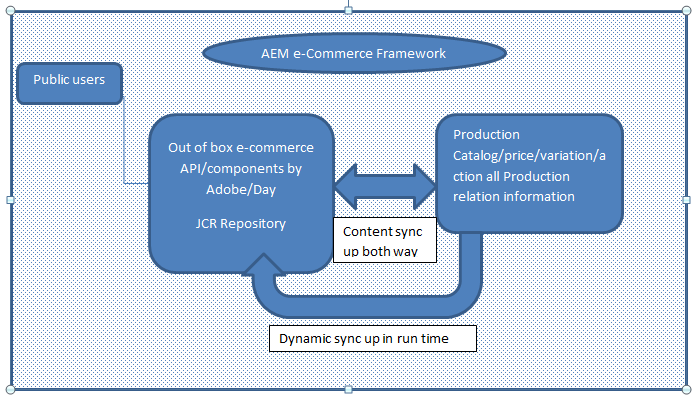
By default outdoor catalog would be available in hybris, you can manually synchronize that content from here http://localhost:4502/etc/importers/hybris.html that will recreate product catalog here /etc/commerce/products. Remember untill you are not customer or Partner with Hybriss you would not get any resource or document about Hybris for functional knowledge.
Generate MVN Project
mvn -Padobe-public archetype:generate -DarchetypeRepository=http://repo.adobe.com/nexus/content/groups/public/ -DarchetypeGroupId=com.day.jcr.vault -DarchetypeArtifactId=multimodule-content-package-archetype -DarchetypeVersion=1.0.2
Provide all other information i.e artifict id, name, group and folders and say yes in the last and finally your maven structure would be created.
Import Project in Eclipse
Download code from github https://github.com/paolomoz/cq-commerce-impl-sample in this case you don’t need to create archetype and maven project creation etc. build and deploy it to your local CQ. Changed ecommorce provide in JCR for Geomtrexx_outdoor and your code would work..

