I worked in start up open source technology company for 7 years and was amazing journey in building platform using Apache ServiceMix, Lifreay Portal, JBoss middle ware suites, Alfresco and many others as integrated solution to achieve business need for large banking, social care in Africa, Europe and Indian market.
I recently had three days in-house TIBCO Training includes TIBCO Business works, EMS, Designer, Active Space , spot fire and other tools related with deployment , Continuous integration and logging framework. Team did great jobs in terms of delivering basic building blocks and architectural nuts and bolts which are required to develop service Web Service, Rest Full Service, querying Database using TIBCO Designer no custom code, it’s all ready made TIBCO provided pallets and Hops and I simply said wow because I am coming from ETL background where ready-made hops and tools saves developers time and reduces risk of long and buggy code for file reading/transformation/querying Database and many more.
Here is one of the sample service designs in TIBCO designer to read some data from database (No Java/.net class no custom code)
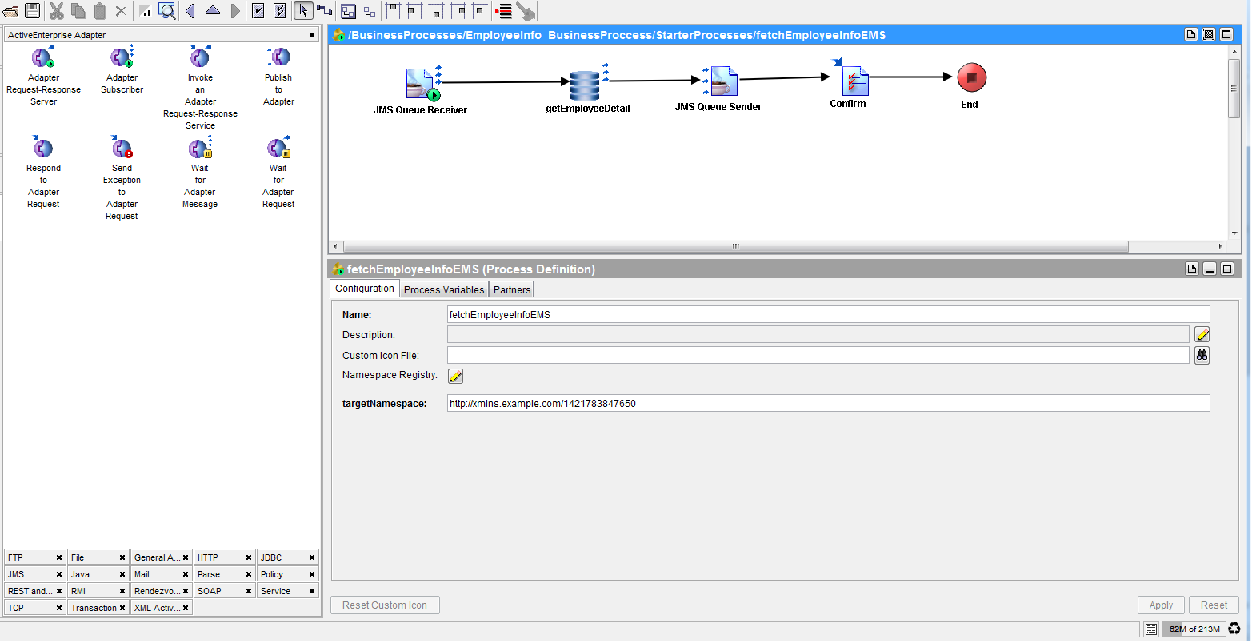
As i software solution architect I am convinced that developing a service is much easier with TIBCO than writing Custom Java or .Net code and writing JSON and other transformation code, it helps to reduce buggy code and faster turnaround time for solution. It can’t be denied Initial development time would be higher for those who are new to this.
NoSQL/Data Grid (Active Space) in TIBCO
I always built robust /scalable low-cost solution based on liferay, alfresco on JBoss and many more .. no software license but supporting thousand concurrent public users. Map/reduce, Lucene, Indexing , SOLR are basic ingredient the solution we developed. I am keen follower of this scalable platform such as Amazon, Netflix , E-Bay, price-line etc .
Active space is new addition to TIBCO suite to support high number of concurrent users in competition of NoSQL/Data-grid/Cache technology which TIBCO claims runs on commodity server, but in Demo I found they are running two nodes on 512 GB memory which are beyond my thoughts why they solution in such a way, later I realized its in memory non-persistent solution where data resides in RAM not on Disk.
Challenge in Adoption Non Relational Approach?
I got a chance to speak few architects who have developed financial platform Microsoft .net for more than decades and very often I hear in leadership meeting reducing downtime , upgrade etc. I always ask question to myself why can’t we move to new generation database and here is reply
“ This new technology and framework are bad adoption and does not fit in our solution, we are very happy with our existing solution and we can scale in this only. New solution are very slow , no documentation so not acceptable blah blah blah”.
Fitting Everything together?
One most important philosophies underpin that one size does not fit all, for many year traditional Database server are used for storing all types, it doesn’t matter all data types fits for relational Data model. General perception is that media, Analytic and social media application are suitable for NoSQL Database and structured relations data but that’s not correct.
Following can be implemented in exciting software to scale and reduce downtime.
- Memcached is used by Both Amazon and Netflix for frequently requested content/data same can be achieved by Active Space to reduce load on database and faster response to user requests.
- Let us stick using highly secure data in RDBMS but active/active set up can be done to reduce downtime and scale it.
- Move other kind of information for example user profile and other data in distributed NoSQL Database and redesign the service.
